Polling reliably at scale using DLQs

Originally published at blog.smallcase.com on July 16, 2019.
Execution of computer programs is blazing fast. It’s only practical to need some delay in execution. Some of such use cases are:
- scheduling a task for sometime in future;
- retrying a failed task with a backoff stratagy
At smallcase, we place orders to buy or sell equities on clients’ behalf. When the order is placed, it’s execution status is not immediately known. We need to poll the partner broker to know the status of order on the exchange.
Intraday traders will tell you that stock markets are time sensitive. Any platform that caters to them needs to be fast and deterministic. Polling for order status needs to happen in a timely manner after regular intervals because an endless loading is never a pleasant sight.

This blog explains the reliability issues we faced with our legacy system for scheduling polling and how we fixed it.
Delay mechanisms:
We will discuss the following delay mechanisms we used in our platform:
Redis Keyspace Notifications
This approach is very simple. We heavily use Redis in our stack, so it was easy for us to use it for scheduling triggers. Redis allows to set keys with expiry using its SETEX command. For instance, setting a key TESTKEY with value TESTVALUE and expiry of 10 seconds can be achieved with:
1 | >redis SETEX TESTKEY 10 "TESTVALUE" |
Parallely, Redis provides Keyspace notifications for data changing events which can be subscribed by clients and can be used to trigger the delayed tasks. Key expiry events can be subscribed using:
1 | SUBSCRIBE __keyevent@0__:expired |
Pros:
- Stateless application code.
The application doesn’t need to store the tasks to perform and delays in its memory. It is outsourced to Redis. - Arbitrary delays.
Delays of arbitrary length are possible without any extra configuration. Just changing thettlparamter ofSETEXcommand will work.
Cons:
- Unscalable.
This strategy works only till there’s only one instance of the application listening to these events. In case this application is to be horizontally scaled, each instance of the application will receive the event because of its publish-subscribe nature. - Unreliable.
The keyspace notifications can get highly unreliable as the number of keys increase. This is clearly mentioned in the docs:If no command targets the key constantly, and there are many keys with a TTL associated, there can be a significant delay between the time the key time to live drops to zero, and the time the expired event is generated.
This worked fine for us in the beginning. But once the orders increased, a lot of clients started reporting really long waiting periods before they could see the status of their orders. On debugging, we saw delays of the tune of 40x and this was the deal breaker for us.
In-memory Timers
As a quick fix to this we used in-process timers. Timers are defined and executed by the application code itself and can be used to manage delays. Node.js provides a variety of in-built timer functions. Setting a 10 second timer is as simple as:
1 | setTimeout(() => { |
Pros:
- Arbitrary delays.
Delay time is controlled by the time argument only. Passing the required delay time in milliseconds is all that is required. - Reliability.
Timers in code are quite reliable. Deviation of only upto few milliseconds is observed.
Cons:
- Stateful application code.
The application adds to its state whenever a timer is set up. It also increases memory footprint of the application. - Unscalable.
In-memory timers do not work well with horizontal scaling. Timer will always trigger the instance which set it in the first place, irrespective of the traffic distribution across the instances.
Timers worked well to mask the problem until we had bandwidth to think about the problem and fix it for good. Now we needed a permanent and reliable solution that would scale.
Dead Letter Queues
After researching a bit about this topic, we decided to try Dead letter queues. DLQ is a sophisticated but robust way to delay message delivery used in message queues like Amazon SQS, RabbitMQ and ActiveMQ.
In very basic terms, a message with an expiry is put into a queue. The queue is instructed to take some action if the messages are expired without being read. We can instruct these expired messages to be pushed to a different queue which is actively consumed by the target application and it simulates sdelayed delivery of message. Following diagram explains this concept:
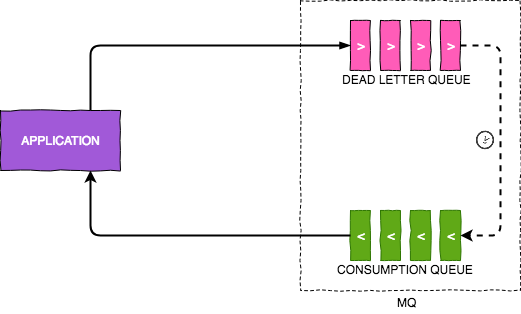
We chose RabbitMQ based on AMQP 0-9-1 for our implementation due to maturity of the protocol and its community.
Pros:
Stateless application code.
The application doesn’t need to store any state. The messages in the queue represent staete in this case.Scalable.
Unlike redis events, message delivery in MQs can be configured to use worker pattern which loadbalances the consumers (subscribing instances of the application) to deliver the message. Source: RabbitMQ docs
Source: RabbitMQ docsReliability.
Message Queues are expected to be highly reliable in delivery of messages. In our testing with RabbitMQ, the results were found to be close to in-memory timers.
Cons:
- Fixed delays.
In RabbitMQ’s implementation of DLQs, the TTL is bound to the queue and applies to all the incoming messages. There is a way to set message level TTL but it has its own caveats. One of the most serious side-effects of using message-level TTL is that a message with higher TTL will block the queue and delay the processing of messages with lower TTL behind it, which is a bigger problem. Hence, we are using DLQs with queue level TTL.
The chart shown below analyzes the average delay observed in resolving the orders we handled in the past year and its relation with the delay mechanism being used.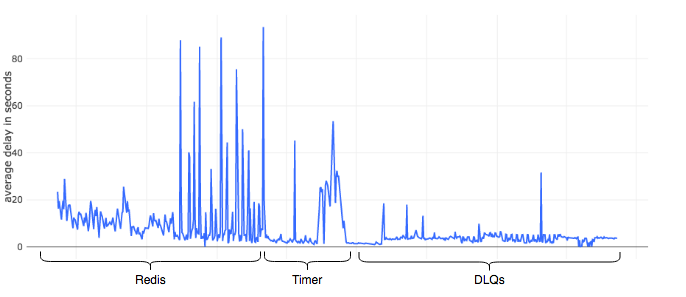
It is clear that the polling delay in Redis was large but consistent to start with but grew out of proportions quickly as the volumes increased. This was quickly fixed using timers but like all quick-fixes, it had a short life too. Finally, we revamped our systems and used DLQs.
It is evident from the graph that DLQs brought consistency to the system.
We traded flexibility with robustness and reliability by using DLQs to manage the delays in our polling for order status. If you’ve solved a related problem in any other way, do let us know in the comments.
❤️ code