Behind the scenes at Access Requests: Worker tasks

Background
Okta’s inbox platform supports various products in Okta’s Workforce Identity Cloud, where human input is required. It is most notably instrumental in the Access Request flow of Okta Identity Governance.
A lot of what we do is trigger-based. These triggers can be a human action — “grant access when the manager approves” — or a time event — “revoke access after 24 hours.” This post will explain how we leverage asynchronous tasks using message brokers like Google Pub/Sub and Google Cloud Tasks to take actions based on these triggers.
Worker tasks
Internally, we call all asynchronous tasks “worker tasks.” We have an internal framework that exposes an interface to create and execute tasks while abstracting away the details of which message broker the task is sent to.
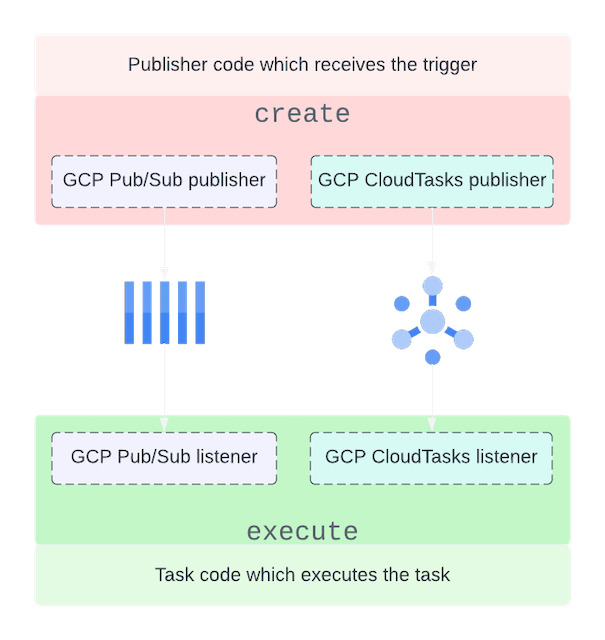
For us, a task is a function that needs to run, along with the metadata that dictates how it runs, in the worker tasks framework. From a conceptual perspective, a task is a collection of certain properties that determine its lifecycle and execution, as shown below:
1 | { |
Most of the metadata is self-explanatory. The driver defines the queue service to route the task from the publisher to the subscriber. In the above example, we are using GCP PubSub with the “fast_queue.”
NOTE: We use Google Cloud Tasks because of its built-in capability to delay the execution of tasks. In all other respects, our Google Cloud Tasks setup is similar to that of Google Pub/Sub. From here, the article focuses on Google Pub/Sub, and similar principles apply to Google Cloud Tasks as well.
Queue setup
Our Pub/Sub setup handles a diverse set of tasks. We’ve set up multiple GCP PubSub queues that allow us to segment the workloads based on traffic characteristics, priority, and the domain of the workload. We do this to ensure:
High-priority tasks get executed faster.
Backlog in processing one domain’s tasks does not affect those of another.
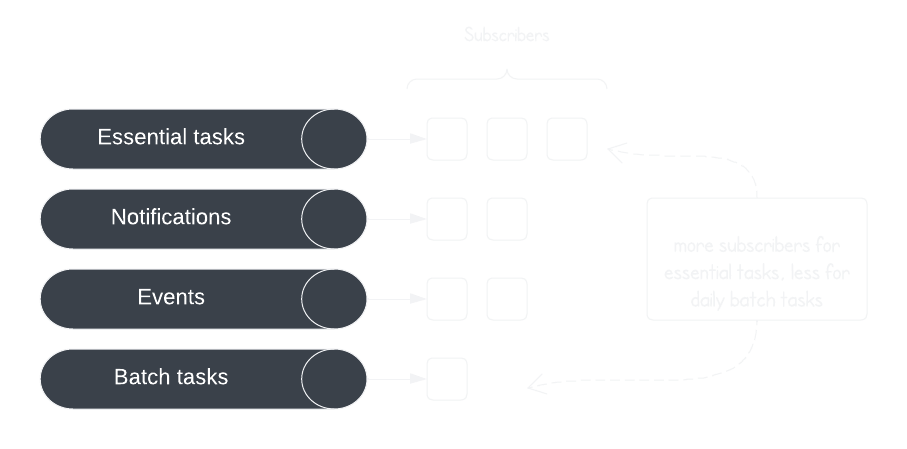
This allows us to scale selectively depending on the task priority. In high-traffic situations, we can easily scale the subscribers for essential tasks and ensure stable platform health while allowing the existing number of notification subscribers to process through the notifications, resulting in slightly delayed notifications.
Flow control
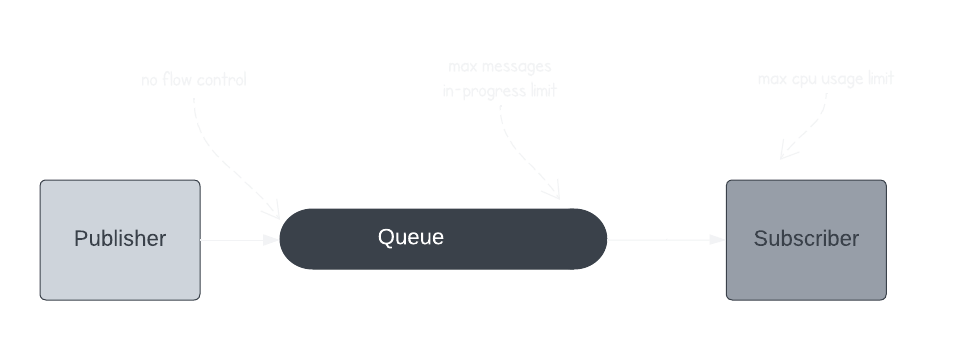
In the previous example, we saw how the queue setup allowed us to scale in certain situations and accept delays in others. Practically, it’s likely that without scaling, the subscribers would get overwhelmed with the increased number of tasks and crash. We solve this by using flow control in various steps. The queues are configured with a maximum number of pending messages they can deliver at a time. This setting allows our subscribers to gracefully handle traffic bursts by managing the flow of incoming tasks.
Unfortunately, it’s hard to nail a magic number of tasks subscribers can handle. Other factors, besides the quantity of tasks, may affect the load, like the complexity of a particular task. Hence, as a failsafe measure, the subscribers are forced to stop accepting more tasks if resources like CPU and memory surpass a certain threshold. In such an event, the PubSub retries exponentially. It’s a naive but effective way to handle as many tasks as possible without crashing the subscribers or scaling up the number of active subscribers.
Trade-offs
Like any other system, there are trade-offs in this architecture. Customers choose Okta because it’s a reliable and neutral vendor. We have the following expectations from our asynchronous task infrastructure.
+ Extensibility
The framework is highly extensible. We can add a new queue service like RabbitMQ, AWS SQS, etc, by adding a driver, making all our tasks compatible with the new services.
+ Reliability
Having a central framework designed with reliability in mind means every new kind of task added to the system gets alerts on failures, dashboard reports, and anomaly detection by default without the task developer needing to do anything.
+ Granular scalability
With our tasks organized into queues based on priorities and domain, we can identify the patterns in delays and make informed decisions about which subscribers need to scale. This process frees our users from staring at loading screens while keeping our infrastructure spending in check.
- Retrying failed tasks
Many tasks in our system have side effects and are not idempotent. Such a task is challenging to recover in case of failure. We run the risk of having double side effects. The framework does not currently have a way to recover or retry these tasks.
What’s next
Our current asynchronous task setup works for our current scale and infrastructure needs. In the future, we’ll be looking to use Google Cloud Functions, which will take the flow control out of the equation. Cloud Functions can scale as needed to process the number of tasks.
Another future improvement we’ve flagged is to increase confidence around “exactly-once” execution of tasks with side effects, like sending emails, which would require using idempotent vendor APIs and more granular checkpoints throughout task execution. Our current architecture provides a good base for these improvements to come.
This article originally appeared on Okta on November 20, 2023.